This post will help you to create autocomplete feature on Elasticsearch.
For Example, if you have a select box and when you search for data you would want to get all results that starts with data.
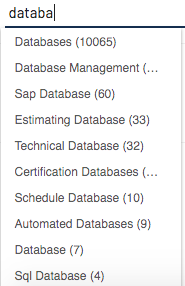
This can be done easily in Elasticsearch. The important thing here is the type of analyzer and tokenizer than you use for autocomplete.
Step 1: Create Mapping with the following tokenizer and analyzer
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | |
autocomplete_search analyzer is used for searching case insensitive words.
Step 2: Test Analyzers
1 2 3 4 5 | |
If you see the results, ES is creating the following tokens. You can change the min_gram based on your needs.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 | |
Step 3: Create data and search
1 2 3 4 5 6 7 8 9 | |
1 2 3 4 5 6 7 8 | |
The results should be
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | |